
Why AWS Lambda with DVC is not a best choice for Data Versioning Pipeline
Introduction
Data versioning is a crucial aspect of machine learning workflows, ensuring that data changes are tracked and reproducible. Data Version Control (DVC) is a popular tool for this purpose, providing a way to version data similarly to how Git versions code.
In this blog, I want to share my experience of attempting to implement a data versioning pipeline using AWS Lambda and DVC. While my goal was to create a fully cloud-based solution, I encountered several challenges that made this approach less ideal.
This post is not about a successful implementation but rather a cautionary tale about the potential pitfalls of this combination.
Use Case
Data Version Control (DVC) lets you capture the versions of your data and models in Git commits while storing them on-premises or in cloud storage. It also provides a mechanism to switch between these different data contents, you can refer to the official DVC documentation here for more details on DVC.
My existing data versioning process involved uploading data to an AWS EC2 instance, where a scheduled cron job would execute a Python script containing DVC and Git commands to version the data and store hashed data files in an AWS S3 bucket.
The problem with this approach is the dependency on the AWS EC2 machine. I am using the machine only to upload the data and run a Python script. Maintaining EC2 instances can be costly, so I thought these basic functions could be done by AWS Lambda. AWS Lambda allows you to run code without provisioning or managing servers and is known for its serverless capabilities and ease of integration with other AWS services.
The new approach I envisioned was:
- Upload data to an S3 bucket.
- Trigger a Lambda function upon upload.
- The Lambda function would handle data versioning with DVC.
- Versioned files would be stored in Git, and hashed files would be stored back in the S3 bucket.
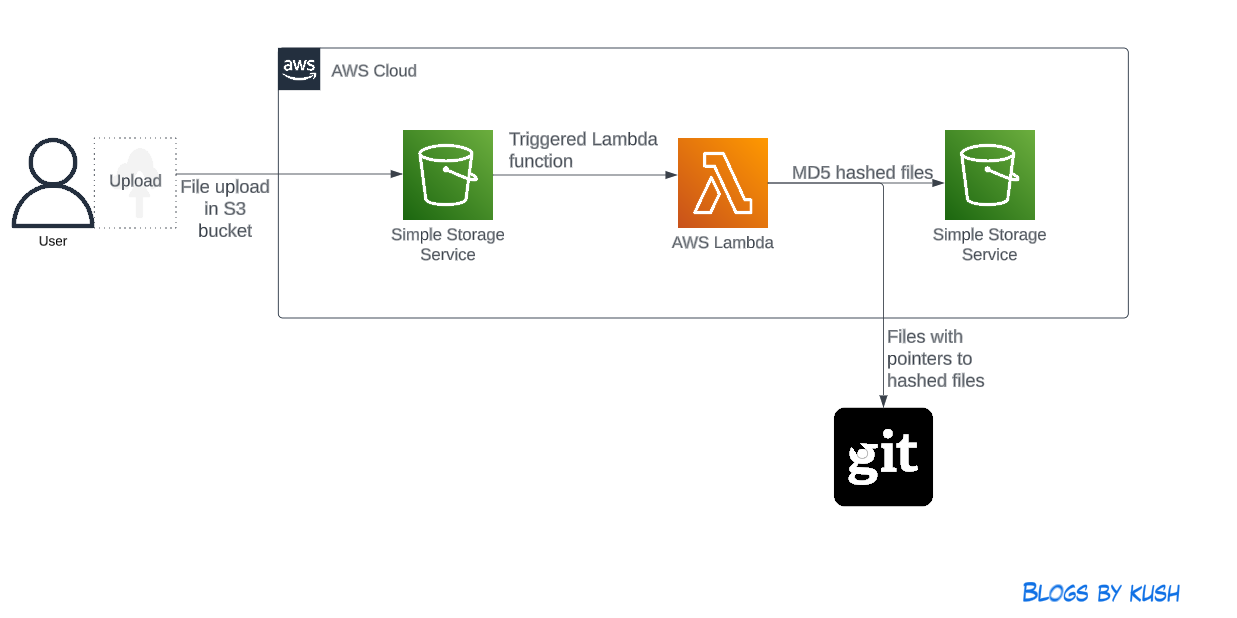 Data Versioning Pipeline
Data Versioning Pipeline
Implementation
There are various ways to create AWS Lambda Functions: you can write them from scratch, upload them as a zip file, or create them from a Docker image. I tried all these methods and encountered several issues with each. For instance, when I tried to create a Lambda function from scratch, I couldn’t run DVC commands because they need to be pre-installed in AWS Lambda. I faced many such issues, but to keep this post short, I won’t list them all.
Therefore, I decided to create the Lambda function using a Docker image. The image below explains the Lambda creation process:
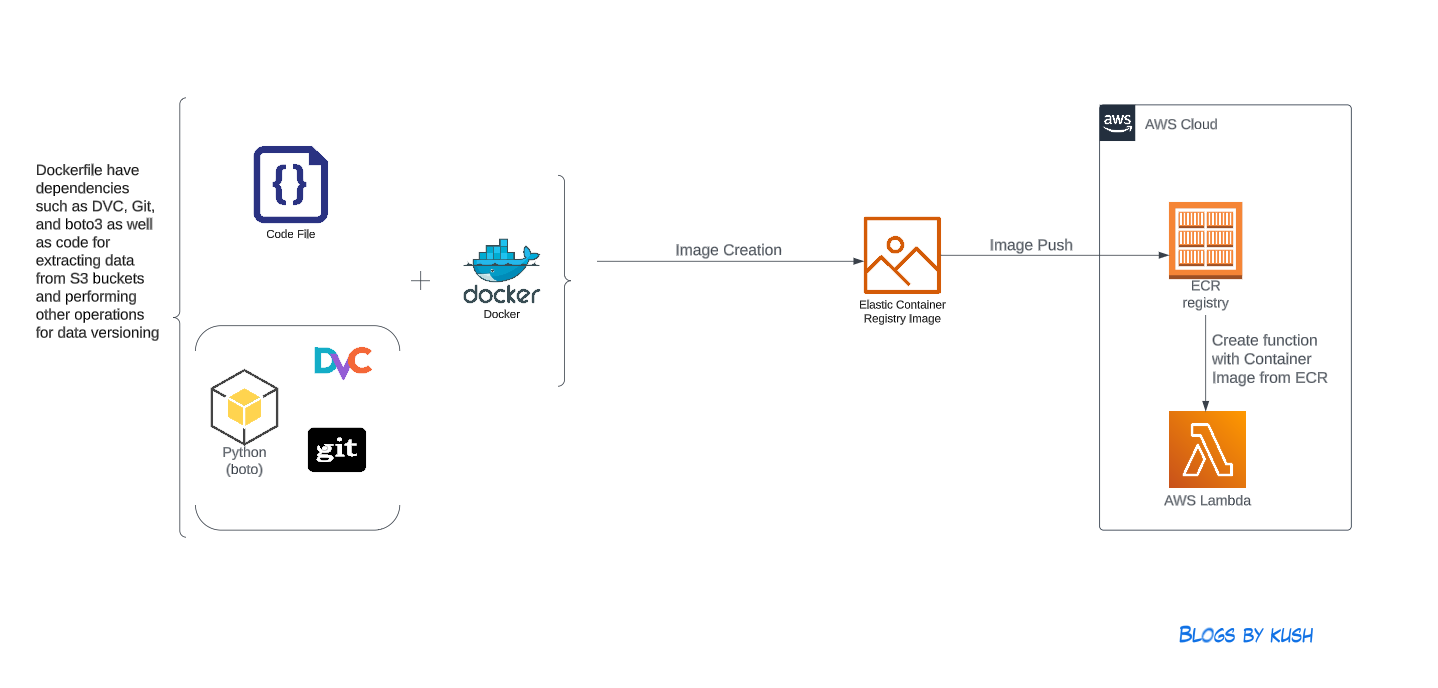
In this approach, I created a Docker image using the following Dockerfile:
FROM public.ecr.aws/lambda/python:3.11
# Installing GIT depedencies
RUN yum update -y
RUN yum install git -y
# Copy requirements.txt
COPY requirements.txt ${LAMBDA_TASK_ROOT}
# Copy function code
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
# Install the specified packages
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "lambda_function.handler" ]
Dockerfile
In this Dockerfile, I copied the requirements.txt file to install necessary dependencies like DVC and boto3 for handling S3 operations programmatically:
dvc
dvc[s3]
s3fs
boto3
Requirement File
Next, I copied the following Python code, which serves as the main Lambda function to execute DVC commands and perform all operations for the data versioning process:
import json
import boto3
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
source_bucket ='mytestdata-upload'
logger.info("New files uploaded to the source bucket.")
key = event['Records'][0]['s3']['object']['key']
logger.info("Copying cloned GIT repo under the temp directory")
os.system("cp -r /var/task/dvc-aws-lambda-s3-dataversioning-repo/ /tmp/")
try:
logger.info("Changing directory to download file from S3 bucket")
os.chdir("/tmp/dvc-aws-lambda-s3-dataversioning-repo")
s3.Bucket(source_bucket).download_file(key, key)
logger.info("Running dvc add command to create hashed file")
os.system("dvc add "+ key)
logger.info("Running git commands to add .dvc file to the GIT repo")
os.system("git add .gitignore")
os.system("git add *.dvc")
os.system('git commit -m "adding data from AWS Lambda"')
os.system("git push")
logger.info("Running dvc push commands to pushed hashed file to the remote storage")
os.system("dvc push")
except botocore.exceptions.ClientError as error:
logger.error("There was an error in versioning process")
print('Error Message: {}'.format(error))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
Lambda Function Handler
The Lambda function handler is the method in your function code that processes events. When your function is invoked, Lambda runs the handler method. Your function runs until the handler returns a response, exits, or times out. For more details about this function, refer to this official document.
To download data from S3, you need to create roles and policies that allow AWS Lambda to access the S3 bucket. This will enable the Lambda function to download the data and perform the required actions.
After creating the Lambda function, the following commands were executed to create and push Docker images and to create the Lambda function:
# 1. Build Docker Image
$ docker build --platform linux/amd64 -t docker-image:dvc-lambda .
# 2. Login to ECR
$ aws --region us-east-1 ecr get-login-password | docker login --username AWS --password-stdin 095******563.dkr.ecr.us-east-1.amazonaws.com
# 3. Create the ECR repository
$ aws --region us-east-1 ecr create-repository --repository-name dvc-lambda --image-scanning-configuration scanOnPush=true --image-tag-mutability MUTABLE
# 4. Build the image - it might take a few minutes to complete this step
$ docker tag docker-image:dvc-lambda 095******563.dkr.ecr.us-east-1.amazonaws.com/dvc-lambda:latest
# 5. Push the image to ECR
$ docker push 095******563.dkr.ecr.us-east-1.amazonaws.com/dvc-lambda:latest
# 6. Create a Lambda function by following command or in console
$ aws lambda create-function \
--function-name dvc-lambda \
--package-type Image \
--code ImageUri=095******563.dkr.ecr.us-east-1.amazonaws.com/dvc-lambda-function:latest \
--role arn:aws:iam::095******563:role/lambda-write-s3bucket
# 7. Test the lambda function
$ aws lambda invoke --function-name dvc-lambda response.json
In the above mentioned steps, the Docker image creation and Lambda function are created successfully, but on invoking the Lambda function, the step that is executing the
dvc addcommand is giving an error. I am covering the reason in the next section.
Learnings
During the implementation of this use case, I encountered several interesting challenges that can serve as valuable lessons for other use case implementations:
-
Lambda Timeout Issue: I was unable to execute basic DVC commands, like
dvc --version, in AWS Lambda. I attempted to run the command via code in thelambda_handlerfunction, which was packaged in a Docker image and deployed as an AWS Lambda function. After numerous attempts, I realized the issue was due to the default timeout value of Lambda. DVC commands in Lambda took more than 5 seconds to respond, while the default timeout configuration was 3 seconds. After increasing the timeout value, I was able to resolve this issue. -
Lambda File System Access Issue:
- Write to the
/tmpPath: AWS Lambda’s file system is read-only except for the/tmppath. If you need to write to the file system in a Lambda function, ensure your code writes to a path inside the/tmpdirectory. - Read-only Error with DVC Commands: Another issue I encountered was a read-only error when executing DVC commands in Lambda. The container image I used was
public.ecr.aws/lambda/python:3.11, where the default directory is/var/task/. Thelambda_handler.pyfunction was copied to this directory when building the Docker image. After cloning the Git repo, I tried running thedvc addcommand, which created a corresponding DVC folder under/var/tmp/, containing some cache and files. This directory is crucial for running DVC operations. However, since all directories except/tmpare read-only, I encountered the following error duringdvc add:ERROR: unexpected error - [Errno 30] Read-only file system: /var/tmp/dvc. To resolve this, I overrode the default path with a path inside the/tmpdirectory by running the command$ dvc config core.site_cache_dir .dvc/site_cache_dir. - User Permissions and Directory Access: While debugging the Lambda function error, I discovered that the default directory
/var/tasks/is associated with therootuser. However, directories created under/tmpare associated with the usersbx_user1051, belonging to group990(Docker usage group). Further investigation revealed that AWS Lambda functions have multiplesbx_usersranging fromsbx_user1051tosbx_user1176. - DVC Add Command Timeout: The
dvc addcommand was timing out. Despite multiple attempts, I could not identify the exact reason. Based on my inspection of folder permissions and access in AWS Lambda, I suspect this issue is related to user permissions. Thesite_cache_dir, which should be created during thedvc addexecution, was not being created, likely due to permission issues. The/tmpdirectory in AWS Lambda is created with the usersbx_user1051, while in Docker, it is usually therootuser. I could run DVC commands as the root user in Docker, but in Lambda, where I executed all commands, everything was under the usersbx_user1051. This discrepancy likely caused thedvc addcommand to fail, and thesite_cache_dirwas not created. To investigate, I created a non-root user with the following commands in the Dockerfile. However, after creating an image from this Dockerfile and logging into the container, I was unable to run DVC commands from the createdsbx_user. DVC needs to be executed as the root user within the container. I’m not sure how to resolve this step yet.
- Write to the
Last Word
Writing this post was tricky for me. First, I have not yet successfully implemented the use case, and I usually write about things that I have fully completed. Second, I faced numerous issues, so the challenge was to present them in a clear and helpful manner without causing confusion. This is one reason this post has been pending for a long time. When I started implementing this use case, it seemed relatively straightforward. However, I quickly realized that creating a fully automated, cloud-based data versioning pipeline using AWS Lambda and DVC was not as simple as it appeared. I hope my learnings can be helpful to others.
Please let me know if anyone else has faced similar issues or has found a way to resolve them.

Leave a comment